
SIVERS NEWS
Overcoming Infrastructure Challenges for the Future of Generative AI
| Category: News
3 October 2023
Overcoming Infrastructure Challenges for the Future of Generative AI
Generative AI – Transforming our lives in amazing ways
Generative AI applications, such as ChatGPT, Google Bard, and DALL-E, are rapidly transforming our lives, enabling users to automatically generate high-quality and creative content—such as copy, images, video, music, code, and more—simply by making requests. It is transforming industries as diverse as digital media and advertising, healthcare, e-commerce, financial services, and public sector, as well as applications such as autopilot, self-driving cars, and more.
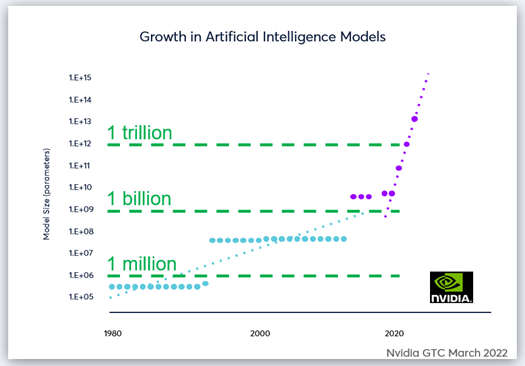
Generative AI models use deep learning to identify common patterns and relationships across massive volumes of data and utilize those insights to create truly remarkable output. Neural network models mimic human cognitive and creative processes to not only create amazing content, but also to continuously learn and improve their results—to the point where the content they create is often indistinguishable from human experts.
As the uses and quality of results of generative AI have expanded rapidly, so have the complexity and scale of the underlying AI models required to produce those results. And that complexity and scale are stretching past the performance and efficiency limits of our current AI infrastructures. Generative AI is quickly approaching a breaking point that, without resolution and innovation, will severely limit its future potential.
Traditional I/O bottlenecks are limiting AI possibilities while increasing costs
Whereas earlier and simpler AI models may have been able to be processed on a single GPU or processor, today’s advanced generative AI models require a massive infrastructure of racks and servers, with each server containing multiple GPUs. For example, Tesla recently unveiled an in-house AI supercomputer to train deep neural networks for autopilot and self-driving capabilities. The cluster uses 720 nodes of 8x NVIDIA A100 Tensor Core GPUs (5,760 GPUs total) to achieve an industry-leading 1.8 exaflops of performance. This type of application drives the need for even faster AI clusters.
While deploying a massive number of GPUs enables IT to expand the infrastructure to handle the ever-growing AI processing tasks, doing so using traditional interconnect solutions creates massive I/O bottlenecks, severely limiting GPU utilization, as far more time is spent waiting for data than processing it.
Thus, more GPUs are required to make up for the performance and compute efficiency penalties, which significantly increases power consumption and capital and operating expenses. To overcome these issues, new, higher-speed, end-to-end interconnects are needed to replace today’s slow, intra-node electrical links and expensive, low-density, pluggable inter-node optical connections.

Expanding AI possibilities at the speed of light
Ayar Labs in-package optical I/O solution—driven by Sivers Photonics laser arrays—replaces traditional intra-node electrical connections and pluggable optical connections used in today’s AI systems with efficient optical interconnect integrated within the GPU and switch packages. This enables data to be transmitted at significantly higher throughput within each node and across nodes.
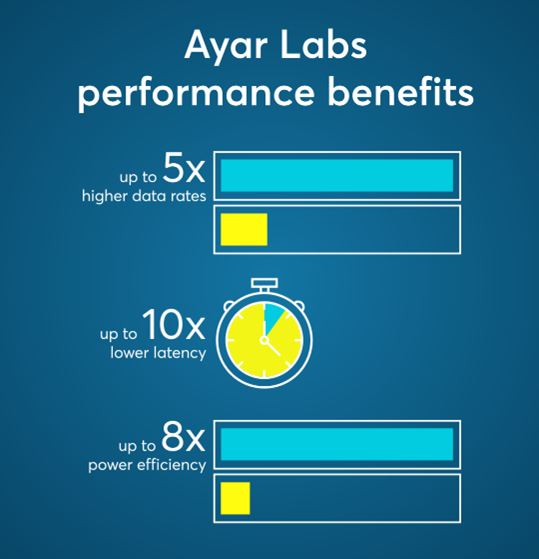
The solution, comprised of the Ayar Labs TeraPHY™ in-package optical I/O chiplet and the SuperNova™ remote light source with Sivers Photonics laser array, offers a solution delivering up to 4 Tbps bi-directional throughput and 10 times lower latency, with up to 8 times the power efficiency versus traditional electrical I/O interconnects.
The solution also provides ultra-high density port counts, enabling cluster architects to connect each node to more nodes and to flatten the network, reducing the number of performance-penalizing hops when moving data across the infrastructure versus bulky, expensive, pluggable optical ports.
Powering optical I/O for next-gen AI architectures
The optical source is a critical component to maximize optical I/O efficiency and scale. The SuperNova remote light source from Ayar Labs uses eight wavelengths of light from Sivers laser array chip across eight fibers, for a total of 64 carriers. This enables each TeraPHY in-package optical I/O chiplet to supply light for 128 channels of data, or 4 Tbps bi-directional bandwidth.
“Sivers Photonics DFB laser array technology is essential to powering our optical I/O solution that is becoming a must-have technology for the growth of advanced generative AI models.” Matt Sysak, VP Laser and Platform Engineering, Ayar Labs

The Sivers Photonics distributed feedback (DFB) Laser Array Technology powers the Ayar Labs SuperNova Multi-Wavelength Optical Source. Built on the InP100 product platform at Sivers 100mm UK wafer foundry, the DFB laser array provides output power of more than 65mW per channel CW operation and 400GHz channel spacing around 1300nm.
The solution is compliant with the CW-WDM MSA specification that standardizes optical sources for co-packaged optics, high-speed I/O, AI, and high-performance computing.
Conclusion
By fueling the infrastructure’s GPUs with data much faster and more efficiently, GPU utilization and system performance skyrocket, enabling architects to build clusters that handle greater, more complex demands with fewer components. The Ayar Labs solution with Sivers Photonics laser technology provides a future path for generative AI’s exponentially larger demands tomorrow.
Sivers will be demonstrating its CW-WDM MSA-compliant distributed feedback (DFB) laser arrays with Ayar Labs SuperNova remote light source. The joint demonstration showcases the 8-wavelength DFB laser array from Sivers Photonics, powering the Ayar Labs SuperNova remote light source. The live demonstration shows two SuperNova remote light source modules, each delivering 64 total wavelengths (8 discrete wavelengths across 8 optical fibers), running without any active cooling.
Learn more about our DFB Laser Arrays.
Learn more about Ayar Labs.